
こんにちは!みうです!
今日は「デコーダー型」についです。LLM調べているとたまーに見かけますよね!
それでは見ていきましょう!
3つのtransformerの形式
Transformerのパーツには以下の種類と用途があります♪
| パーツ名 | 主な用途 |
| Decoder型 | LM(言語モデル) |
| Encoder型 | ベクトル検索 |
| Encoder-Decoder型 | 要約や翻訳など |
Decoder型
さっくりこんなイメージです
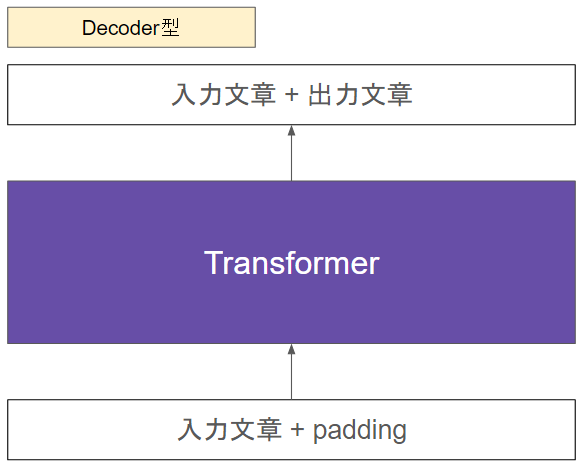
Decoderというのは、名前の通り、本来は”出力すること“が役割です。入力した文章をそのまま出力するだけです。LLMにおいてはpadding tokenがある部分に生成を行います。
詳細はこちらを読んでください♪
実際のところ、あまりLLM以外では見かけない使い方です。
Encoder型
さっくりこんなイメージです。
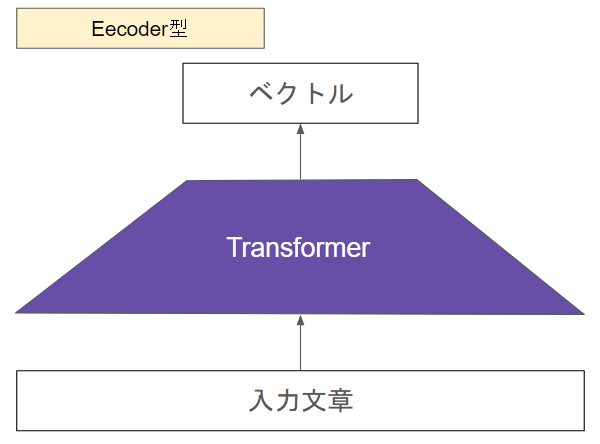
文章を入力してベクトルを出力します。LLMのように文章は生成されません。
このEncoder型のモデルはよくRAGで使用されます!
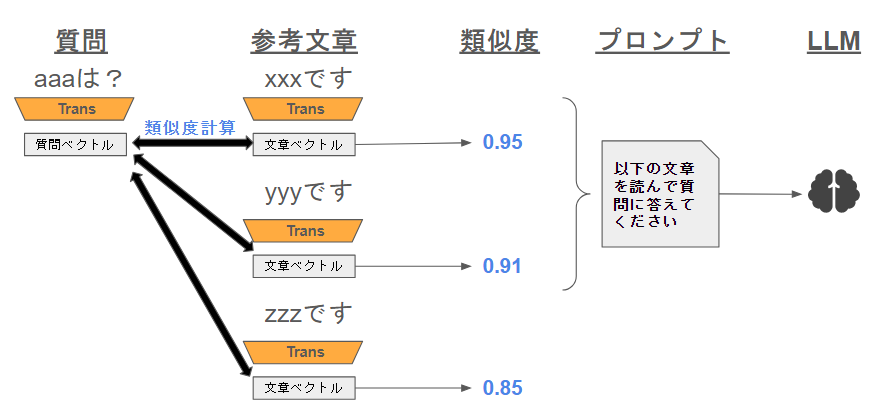
質問や参考文章をベクトルにします。このベクトル同士で類似度を出力して関連文書上位を抽出してLLMに回答させます。
RAGの精度を求める上では非常に重要なパーツです♪
Bi-Encoder
Bi-Encoderは2つのEncoderを使って文書の類似度を計測する方法です!
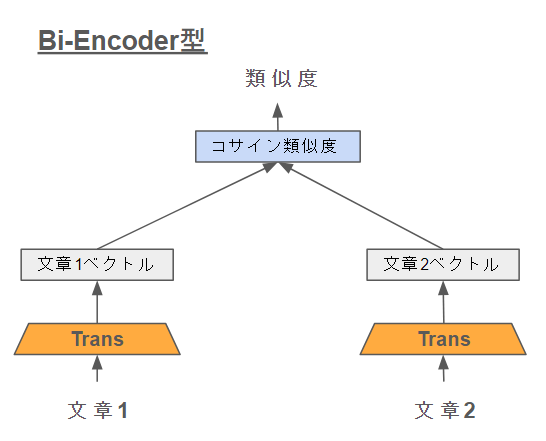
Bi-Encoder形式のメリットは
- 事前に参考文書側をベクトル化して保存しておくことで、使う際にはクエリだけベクトル化すれば良い(クエリ時は高速)
Bi-Encoder形式のデメメリットは
- 前処理に時間がかかる
- 精度的にはそこそこ。(単純にベクトルが似ているかどうかでは限界がある)
Cross-Encoder
質問も参考文書群も入力して、その文章同士の類似度を出力します。
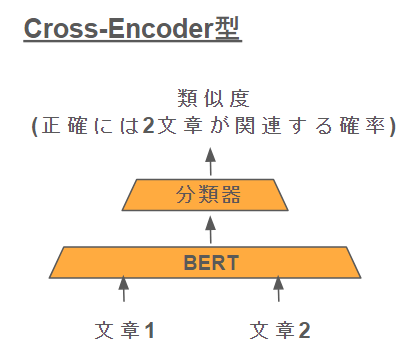
そのため、Bi-Encoderにあった類似度計算はなく、この類似度計算の構造そのものを内部に取り込んでしまったような構造をしています。
Cross-Encoder形式メリット
- 比較する文章を両方とも1つのモデルに入力し、精度高い
Cross-Encoder形式デメメリット
- 全参考文章を質問回答の際にベクトル化するためクエリの際に時間がかかる
- 多くの文章から関連文書を探すのは不向き
Encoder-Decoder型
Encoder-Decoder型は一昔前までは翻訳や要約で非常に使われていたアーキテクチャでした。近年はLLMにそのポジションを取られつつあります。
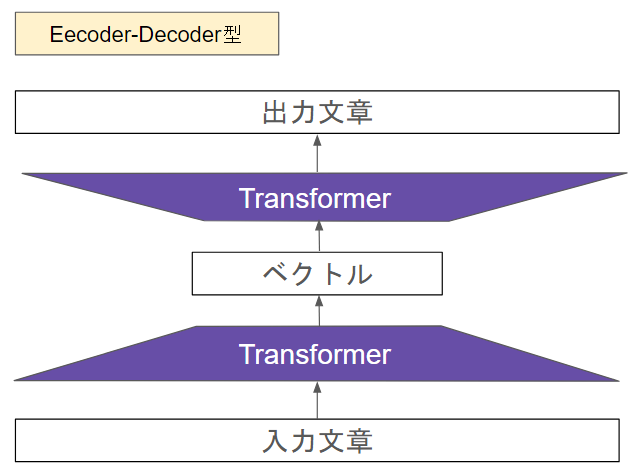
基本的には、LLMではなくBERTなどでも散られている構造で、
入力: はじめまして
出力: Nice to meet you.
となるように学習されます。
DecoderとEncoder-Decoderの比較
翻訳をする場合は以下のイメージです
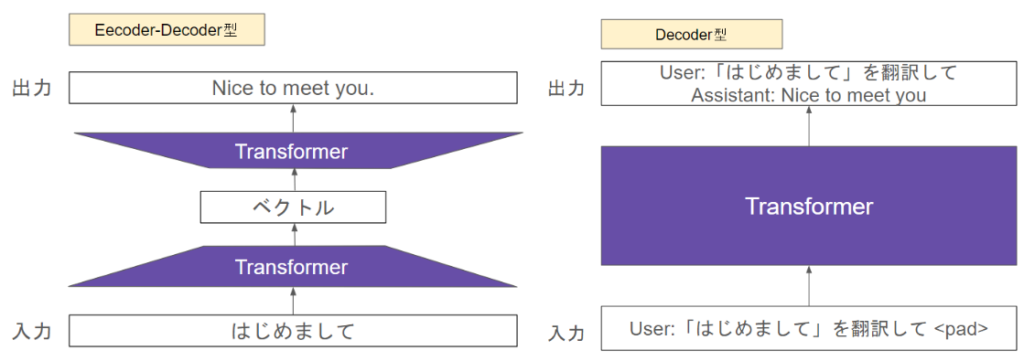
Encoder-Decoder型の場合は、入力した文から直接そのタスク(翻訳)を行うことに対して
Decoder型は、入力文の続きを予測する形でタスク(翻訳)を行います。
まとめ
LLMはデコーダー型、のようなことをたまに聞きますが、あまり意味がよくわかってない人も多いかなと思いまとめてみました♪
豆知識としてみなさんの役に立てば幸いです!ありがとうございました!

