こんにちは!みうです!本日はTransformerです!
Stable Diffusionでも使われていますし、LLMでも使われている非常に重要なパーツです。しかしこのTransformerが物凄く分かりづらい構造をしているのですよね😥
AIやっている人でもなかなかに分かりづらい代物です。
今日はそのTransformerについて、なるべく分かりやすくして解説してみたいと思います♪
多少長くなっても図を増やして少しづつ解説したいと思います
ちょびっと歴史
Transformer2017年にgoogleの研究者により発表されました。
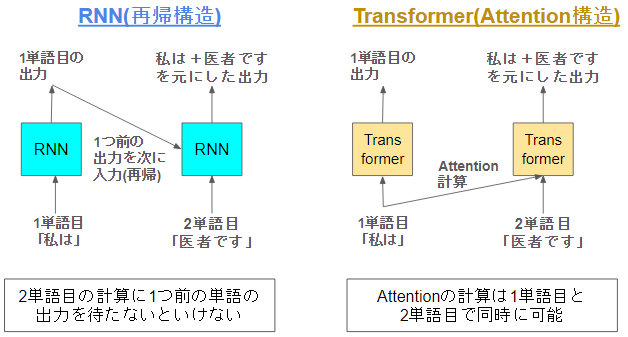
それまでの自然言語処理のベースラインはRNNのような再帰構造を持つLSTMやGRUが主流でした。
この再帰構造をもつ構造は順番にデータを入力することで時系列データを処理します。しかし、逆に言うと「順番に入力しないと処理できない」という欠点がありました
計算に時間がかかりますし、順番に入れると最初の方に入れた単語を忘れちゃったりします😅
そこで考えられたのがAttentionを使ったTransformerという構造です。TransformerはRNNの弱点を補う以下の特徴を持ちます。
- 再帰性を排除してAttentionを採用
- 順番待ちがなくなり学習が効率化
- Attentionになり過去の単語が直接出力に作用するため忘れづらくなる
Transformerの構造の全体感
さて、Transformerの理解に進みましょう!すこーしずつ進めていくのでゆっくり理解してください♪
この記事では、理解やイメージをしやすくするために「文字」という表記をしますが、実際にLLMにはトークンが入力されています🐭
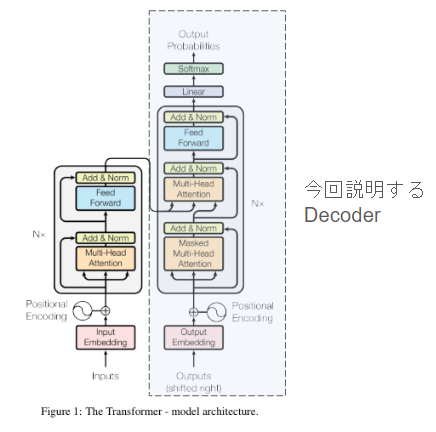
①今回説明するTransformerのパーツ【Decoder】
LLMはこのよくある図のうち、右側のDecoderというパーツしか用いていません。ただ、それでも十分Transformerについてよく知れると思います。この記事では、このDecoderさんについて説明していきます。
②最小単位1文字のTransformerを見てみる
1文字TransformerのDecoderはこんな感じです。
例文として、「私/は/教師/です/。」(5分割)という文章を入力してみましょう♪
入力: 私
出力: 私
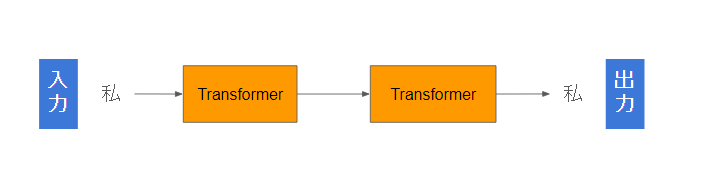
何となくふしぎですが、「これであっています」。まずはTransformerとはとりあえず、入れた単語をそのまま出力する構造だとご理解ください
Transformerの文章処理における”入力”は、文章ではなく文字単位や単語単位であることをご認識ください!!
③2文字のTransformer
次に、入力を2文字にしてみましょう!
処理はこんなイメージになります。
入力: 私/は
出力: 私/は
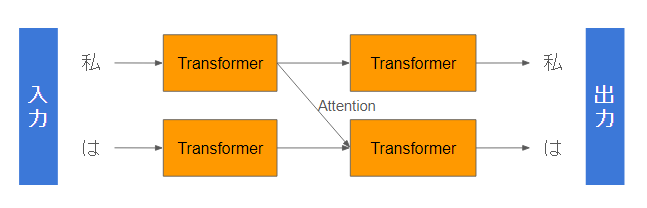
入出力は同じですね
一方、中間でワチャワチャしてますね。そうです、これがアテンションです!
このアテンションの計算についても説明しますが、全体感から見て行きましょう♪
④5文字のTransformerの処理
すべての文章を入力した場合はこのようになります。
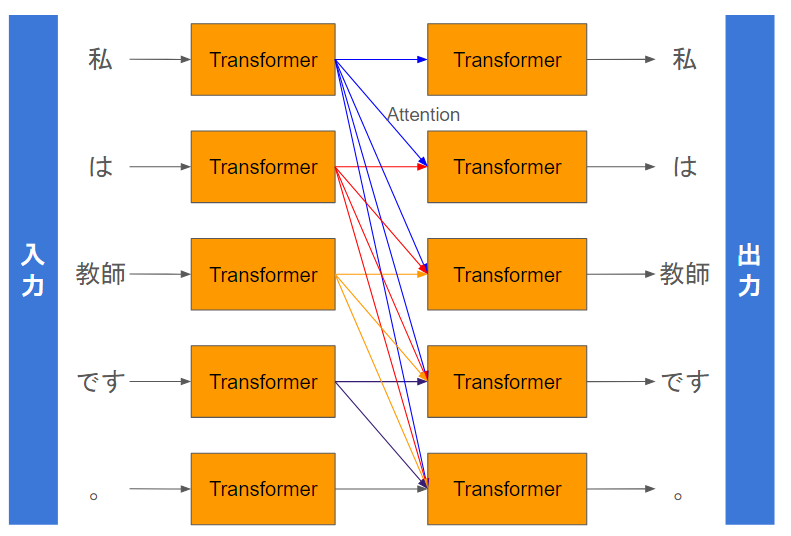
4文字目の場合は、1-4文字目に対してアテンションが計算されて、1-4文字目の出力を重みづけして足し合わせます。
5文字目の場合は、1-5文字目からアテンションが計算されて、1-5文字目の出力を足し合わせます。この重みは重要度や関連度の高い文章ほど高い値になることが期待され、重要な単語同士を重要視して計算されます。
Transformerにおいて1単語ずつTransformer処理を行う中で、それぞれの単語同士がAttentionで足し合わせて混ざり合います🥐
ここまでのまとめ
ここまでの説明で、以下の点をご認識いただけると幸いです♪
- Transformerは再帰構造を持たず、Attentionで時系列を表現すること
- Transformerの入出力は単語(トークン)単位であり、文章単位でまるごと入れるわけではないこと
- Attentionとは、トークンごとの出力を重み付き和すること
次はTransformerの内容をもう少しブレイクダウンしてみてみましょう!
Transformer単体の入出力とアテンションの計算について
Transformerは、単体ではざっくり以下の入出力となります。
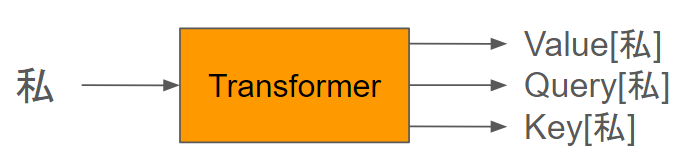
この3つを合わせてqkvと書くこともあります。それぞれ役割があります。
| パーツ名 | 役割 |
| Value | 単語を表現する特徴量の本体。「入力トークン私を表現する特徴量そのもの」 |
| Query | アテンション計算のうち、「私」を表現する鍵のようなパーツ。 |
| Key | アテンション計算のうち、私と関連する何かを表現する、鍵穴のようなパーツ。 他のトークンが私との関連度を測るのに使用する |
各単語ごとに計算されるのでこんな感じになります。
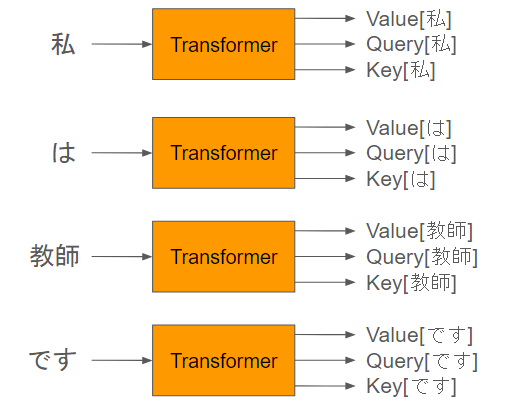
QKVを使ったアテンションの計算
LLMは、前→後にアテンションが伸びるので、「です」に向かってアテンション計算のイメージをなぞってみたいと思います!
①「です」のqueryを注目します。
対象としている単語のTransformerの出力するQueryにまずフォーカスします。
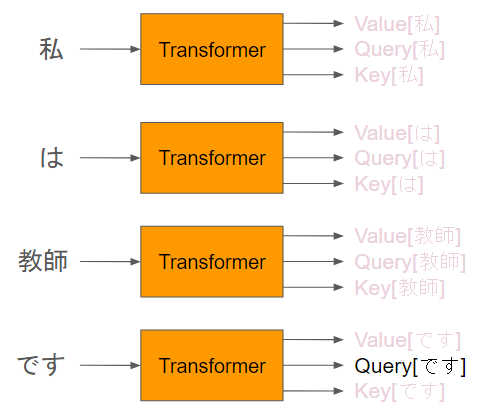
②それより前の単語のkeyを集めて内積を取ります
このQueryに対して、ほかのTransformerのKeyを集めて、内積を計算します。これがAttentionの値です。
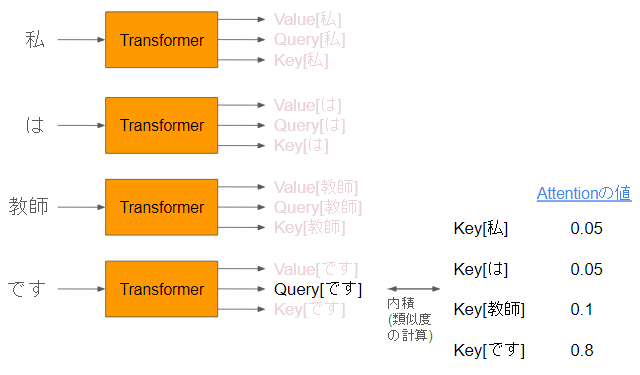
Softmaxとかルートで割るとかありますが、一旦細かい話ということでスキップします。
重要な点として、「アテンションの計算は内積という掛け算を計算するだけ」という点を頭の端っこに置いておきましょう🔥
③内積で計算されたAttentionを元に、Valueを合計します。
各トークンのValueに対して、各Attentionを掛け合わせ、重み付け和としてします。
Query[です]から計算されているため、合計したものは、Value[です]になります。
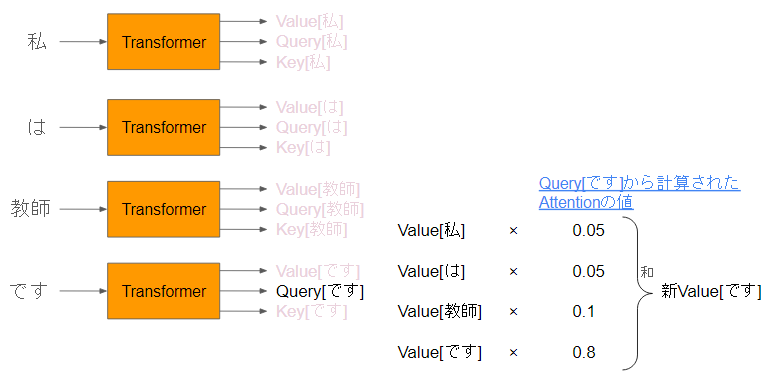
④各処理の結果はまとめるのこのようになります。
同様の処理を各トークンで行います。さらに、その結果は次のTransformerにそのまま入力されます。

⑤実際のLLM
実際にはこのTransformerブロックを数十~百オーダー積み重ねて推論が行われます。
7Bと70Bの違いは、このTransformerブロックの”深さ”になります🚅
このパートのまとめ
- Transformerは、QueryとKeyとValueを出力する
- 各Queryが、それぞれのKeyと類似度を計算してAttentionを計算する。
- Attentionの重みに従って各Valueの和を取り単語の特徴量を足し合わせている
- そのValueの和を次のTransformerの入力としてまた用いている
文章生成の仕組み
さて、この図からある疑問がでますよね
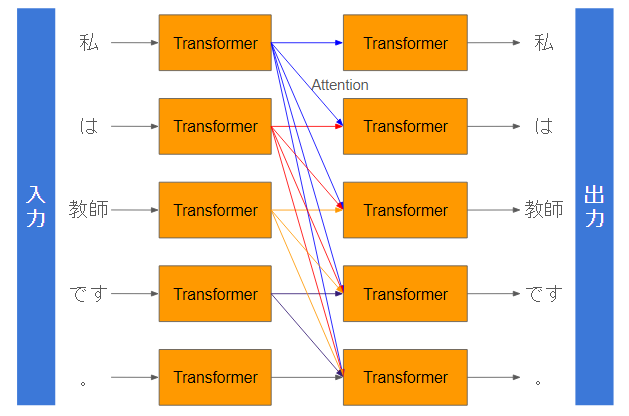
文章は生成されてなくない?
そうです。文章生成をするためには、もう少しトリックがあります。
padding tokenの追加
文章を生成させるために工夫が必要です。
見てきたとおり、「Transformerのデコーダーパーツは入出力の文字数が一致」します。
そのため、文章を生成するには、「padding token」という「ここに穴埋めしてくださいトークン」を入力します。そうすることで、この「穴埋めトークン部分」に「新しく文章」が生成されます。
入力: 入力5文字+padding token 2個
出力: 入力5文字+生成文章2文字

これで生成が出来まるようになりました♪
こういう仕組みのため、OpenAIの課金は入力トークン数+出力トークン数で課金されるんですね😃
その他のパーツについて
ほかにもpositional encodingやembeddingなどのパーツがありますので簡単に触れておきます!
positional encoding
Transformerは、attentionの計算とそれに基づく重み付け和という意外とシンプルな構造でした。この時、「和」には当然順番がない訳ですから、語順のような情報が無くなってしまいます。
例文① 私+は+ハンバーガー+を+買いました
例文② ハンバーガー+は+私+を+買いました
例文②は明らかにヤバい文章ですが、順番の関係ない足し算という観点では、例文①=例文②になってしまいます。
そこで、positional encodingは、単語に位置関係の情報を渡します。
私=私+pos(1)
は=は+pos(2)
という感じで、position情報をそのまま足して渡します
足すだけでいいんかい、というのは意外ですよね
このpos(1)はモデルにもよりますが、円形のsin/cosを採用してるのがメジャーです。イメージだと以下のようになります。
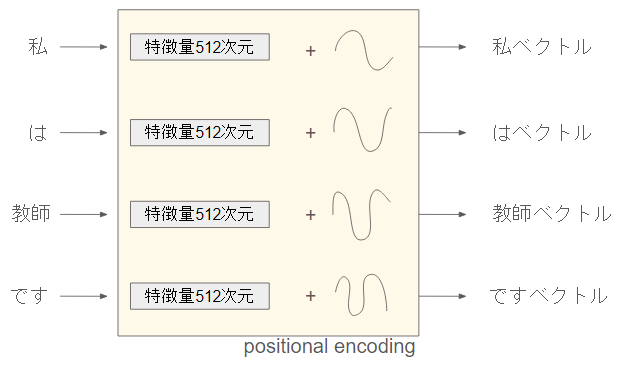
(手書きでスイマセン)
こんな感じでsin/cosを足し算してます。
モデルの最大シーケンス長(推論できる最長トークン)は、基本的にこのpositional encodingの仕様で決まります
Token化とOnehot-encodingとtokenのベクトル化
この辺はTransformerに入れる前処理です。AIには文字は直接入力できないため、ベクトルに変換してから入力する必要があります。

こんな感じです。ベクトルに変換したうえでTransformerに入力します。
Decoding
最終層には同じ逆にしたような構造になっています。

補足と注意事項
- 細かいところで、簡潔に表現している部分があります。ご容赦ください
- 本解説は、”LLMで使われるTransformer”を解説しています。BERTやViTではまた違う使い方となっています。
まとめ
今日はTransformerについて解説してみました!
長かったですね!参考になれば幸いです!ご拝読ありがとうございました😉

