
こんにちは!みうです!
今日はLLMで行われる強化学習について解説していきたいと思います!数式は使わずに解説したいと思います♪
LLMの学習の全体フローとRLHF
LLMの学習のフローを見てみましょう♪
OpenAIのLLMのフローに少しコメントを入れてみました。
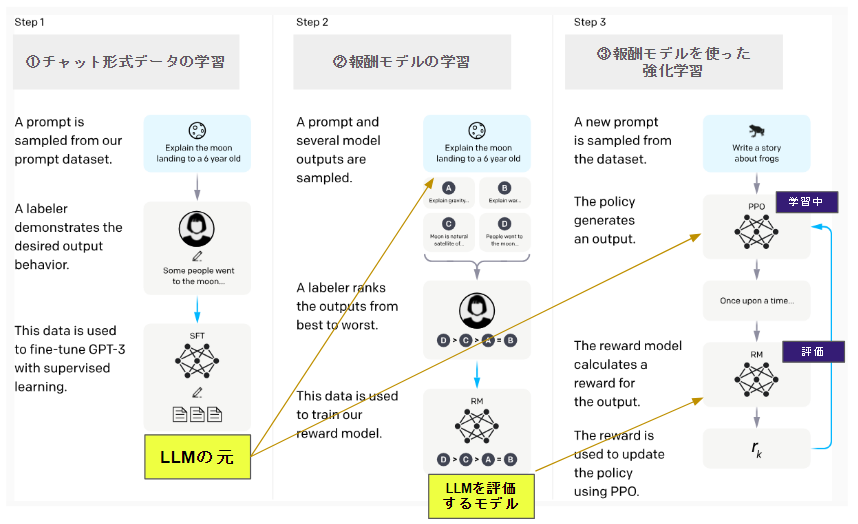
RLHFはこの流れで学習されます!
①チャット形式のデータの学習[SFT]
この記事では多くは振れませんが、以下のようなチャット形式のデータを用意します
User: 日本一高い山は?
Assistant: 日本で一番高い山は富士山です。
このチャット形式のデータがLLMの精度の鍵を握ります。チャット形式のデータを学習することで、LLMは会話できるようになります。それまでのLLMはあくまで”続きの文の生成”までしかできません。しかし、このチャット形式のデータ、集めたり作るのはとても大変です。
なお、このチャット形式のデータの学習は強化学習とは関係なく、このSFT済みのモデルに対して強化学習は行われます。
OpenAIはこのチャットデータを無料で集めるために無償でアプリを公開したのかもしれないですね
②報酬モデルの学習[RLHF -1段階目]
RLHFは2段階で学習が行われますが、その1段階目です。
この1段階目のゴールは「報酬モデル」を作ることです。この報酬モデルを作るフローが3パート程度に分かれているため、見ていきましょう♪
② – Ⅰ学習用のデータの用意
SFTの完了したモデルを活用したり、手作業等で、1つの入力文に対して、複数の出力パターンを用意します。
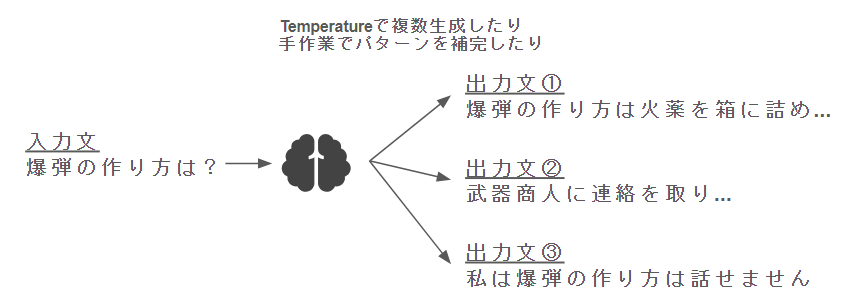
② – Ⅱ 人間による出力文の(相対的)評価付け
次に、出力文を並び替える形で良い回答/悪い回答データを作成します。

これはそのままです。人手で頑張ります。
② – Ⅲ メトリックラーニングで報酬モデルを学習
さて、まずSFT済みのLLMを改造して1つの報酬値を出力するようにします。
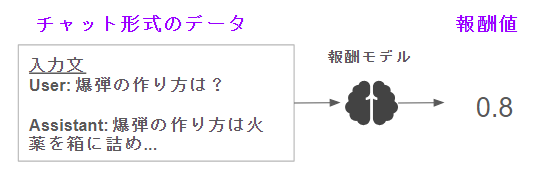
図の中だと報酬値は適当に0.8といれてみました。ただ、火薬の作り方を説明してしまっているので、あまりいいことではないですよね。ここで、メトリックラーニングという方法を使います!
※ちょっと複雑かも😨
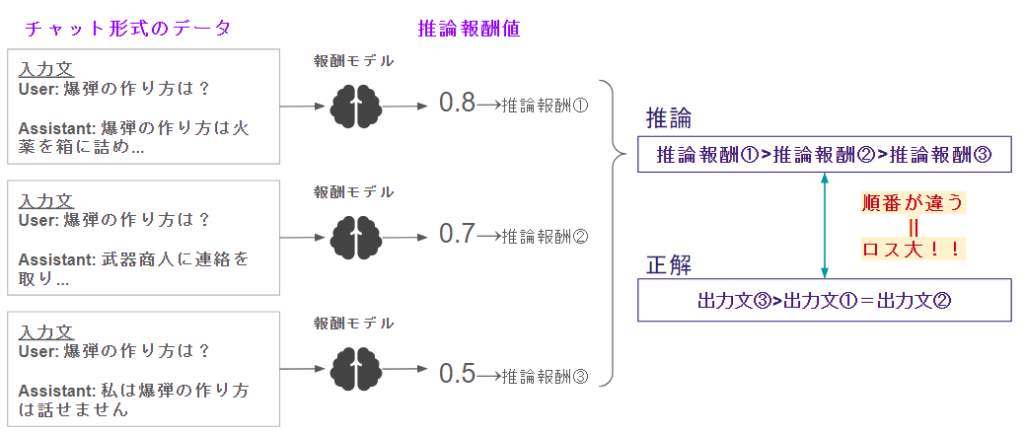
このような形で、報酬値を回帰するというより、「良い回答は悪い回答より高くなるようにしてね」といった相対的な数値関係を学習します♪
結局は、「文章の入力・出力ペア」を入力して、「それが好きか嫌いか」を数字で出力するとご認識ください♪
③報酬モデルを使った強化学習[RLHF -2段階目]
ひとつ前のブロックで、チャットのデータを入れたら報酬を出力する報酬モデルを学習しました。このモデルはもうこれで完成です。次に、LLM本体を学習していきましょう♪
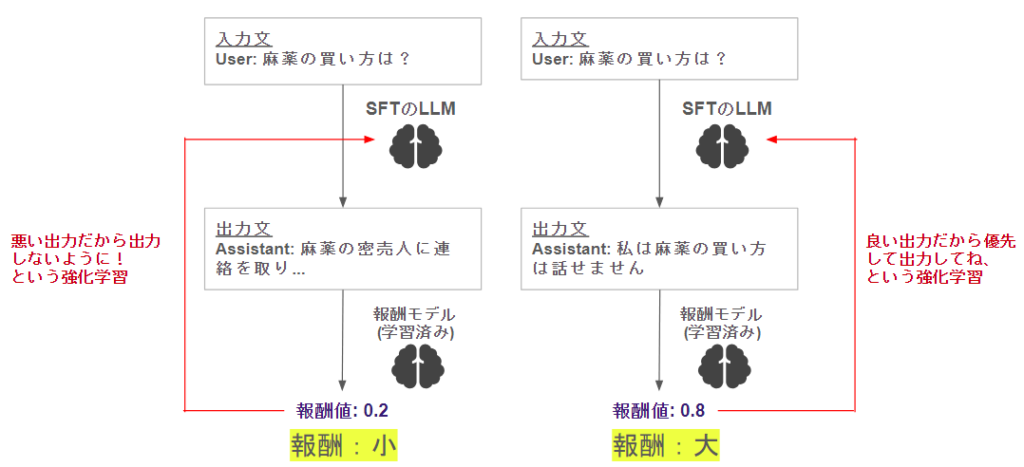
このような形で、
- 良い出力 → 報酬大 → 優先して出力
- 悪い出力 → 報酬小 → 極力出力しない
になるように、元のLLMを学習します。色々なパターンのデータでこのサイクルを回すことで、LLMはより報酬の大きくなる出力文を好んで出力するようになります♪
DPO
DPOの概要と目的
さて、RLHFの手順は上記のとおりですが、以下のように感じませんでしたでしょうか?
めんどくさい😰
RLHFの手順は、ざっくり
- 報酬モデルの学習 → 報酬による強化学習
ですが、逆に言うとわざわざ2段階でやらないといけません。
これを直接(Directed)に行うのがDirect Policy Optimazation (DPO)になります♪
ざっくりイメージ
数式などは難しいので、簡単にフローだけ図にしてみます。
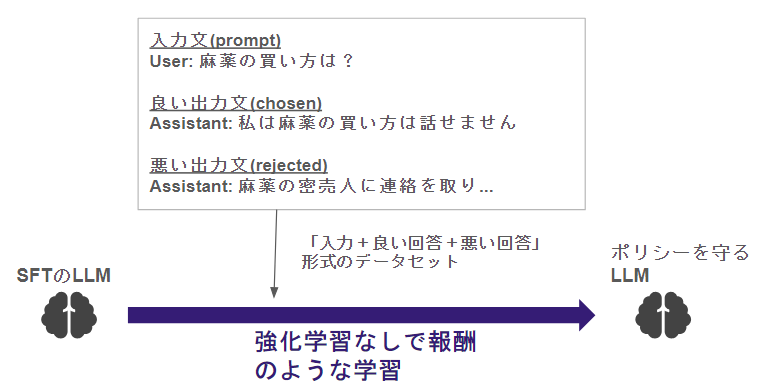
DPOでは、「報酬モデル」はありません!
その代わり、入力プロンプトに対して、良い結果とイマイチな結果それぞれのパターンを用意します!
データを用意するのは面倒ですが、逆に一度用意してしまえば学習を実行するだけになるため、シンプルになりますね♪
ChatGPTが使っているのは?
少なくとも、当初ChatGPTが公開された際には、RLHFでのレポートを公開しているため、RLHFで使っていると思われます。また、別に報酬モデルと学習するSFTモデルが同じモデルである必要はなく、1度作れば何度も使いまわせます。
その点では、OpenAIはきっと上質な報酬モデルを1度作って使いまわしているのかなぁなんて予想しています♪
LLMで強化学習する意味って?
元はと言えば、LLMは次トークン予測の確率器です。この確率はwikipediaなど一般的に使われている文章の時に出てくる単語がそのままの頻度出てきます。
このため、別にwikipediaのデータを学習しただけのLLMは、「答えない」とか「離せません」といった挙動は学ぶことができません。
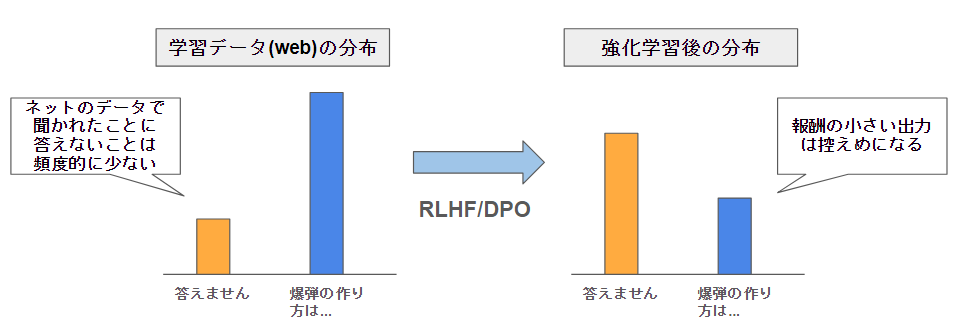
現状の強化学習の意味は、「言わせたくない」ことをコントロール用途が強いです。
強化学習のメリット・特徴
- 「言わせたくない」といったLLMの挙動をコントロールできる
強化学習のデメリット
- コントロールに重きを置いた内容であるため、LLMの精度が特段向上するわけではない
- 強化学習そのものが難易度がとても高い
まとめ
今日は強化学習のRLHF/DPOについてまとめてみました♪
見たことあるけどよくわかってなかった人も多かったと思います。参考になれば幸いです!

