
早速ですが、まずはこのOpenAIのサイトで実例を見てみましょう
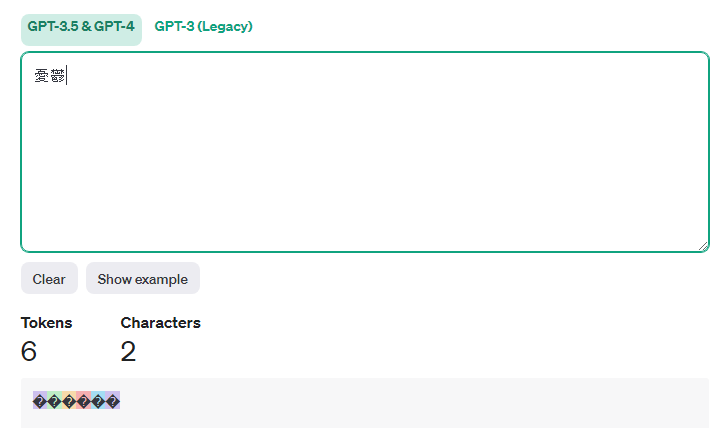
「憂鬱」は漢字で2文字、音でも「ゆううつ」で4音、にも関わらずOpenAIのトークン数は6です。多い!😅
この記事では、なぜ6トークンになってしまうのか、その原理から理解してみましょう♪
ここが日本語特化していないLLMの特徴ではあります。
トークン化の仕組みの前に
まずは少し自然言語処理の背景的なとこに触れておきます。
憂鬱=1単語=1文字
でも良くないか、思いますよね。
大丈夫です。そういう分析は今でも行われています。この場合は、Mecabなどの「辞書」を用意して、辞書にある文字列を「単語」として扱います
この辞書を使う形式は良さそうに見えて厳しい前提があります。

「時代と共に変化する言語に対して辞書の更新があまりに大変すぎる」
そのため、LLMでは、こういった辞書を最初に用意する訳ではなく、データドリブンなBPEという方法を使用しています!
あと開発者の知らない言語の辞書を整備するのは難しいですよね
トークンのベースとなるUTF-8
OpenAIのモデルはかなり多くの言語に対応しています。日本語も日本人しか話さない言語であるにも関わらず、あの高い精度です。
Openaiのトーカナイザーは全世界ほとんどの言語に対応する文字コード、UTF-8をベースにされています。
まずは、UTF-8で文字を変換してみましょう
あ=/e3/81/82 (3byte)
優=/e5/84/aa (3byte)
a=/61 (1byte)
こんにちは=/e3/81/93/e3/82/93/e3/81/ab/e3/81/a1/e3/81/af (3byte×5)
Hello=/68/65/6c/6c/6f (1byte×5)
今日は意味がわからなくて良いです!ただ、日本語って3バイトから構成されてるんだぁ、くらいの感想を持ってくださいませ!
漢字がトーカナイザーで3トークンな理由が見えてきましたね
BPE(グループ化)
このままだと、1文字=1トークンのようなとても効率が悪くなってしまいます。
そこで、BPEという形でグルーピングをしていきます。
端的に言うと、「よく出てくる単語列はセットにしてしまおう!」という感じです。
例えば「Hello」は英語のデータの中でよく出てきますよね
Hello = /68/65/6c/6c/6f = 1トークン
としてしまおう!という形です。
当然日本語においても、良く出てくる単語はグループ化されてトークンが効率化されています。
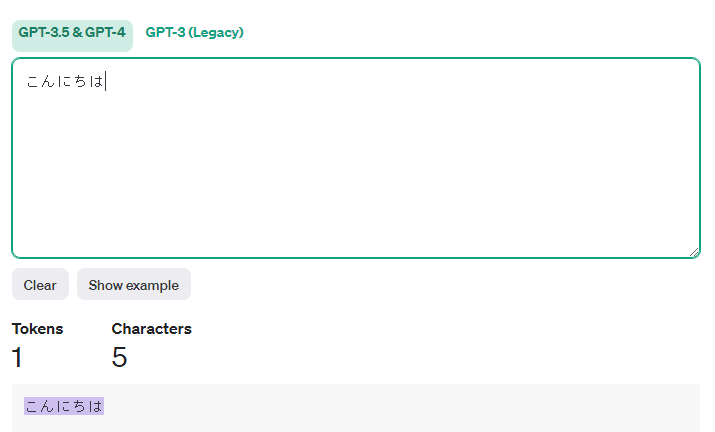
このようにセットになっています。なお、あくまで「こんにちは」が良く出てだけであるため
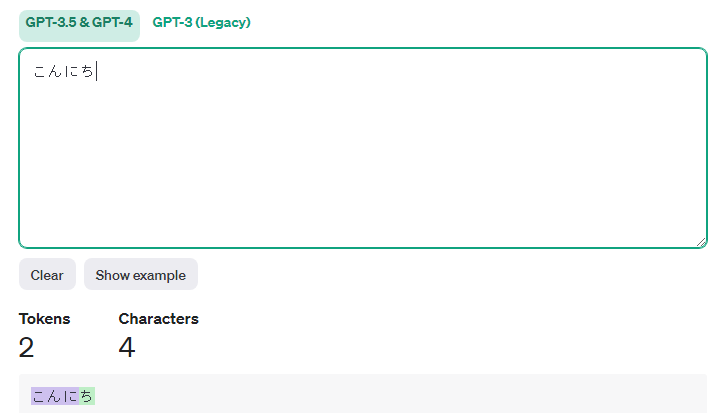
「こんにち」にするとトークンは増えます🤣
いかがでしたでしょうか♪ 「文字」→「UTF-8エンコード」→「グループ化(BPE)」→「トークン」と推移することで、日本語の漢字は1文字で3トークンになるし、5文字で1トークンになる場合もあります😎
という訳で、OpenAIのトークン効率は英語がベストに
OpenAIの学習データはかなりの割合が英語です。
そのため、データから効率化をする過程でトーカナイザーも「英語に特化した」物になります。一方、これは”アルファベットに有利”なわけではありません。事実として、フランス語やドイツ語も日本語ほどではないとはいえ、トークンの効率は英語よりも悪いです。
| 言語 | トークン効率(英語比) |
| 英語 | 1.0(基準) |
| 日本語 | 2.3 |
| フランス語 | 1.6 |
| ドイツ語 | 1.58 |
| 中国語 | 1.91 |
一般に日本語特化のLLMは、この効率が日本語に向いていることが多いですし、このトークンが日本語向きでは無ければちょっと日本語特化のLLMとは言いずらいですね😅
皆様のちょっとした疑問が解決していれば幸いです!

