
こんにちは!みうです!
今日はRAGのざっくり仕組みと、作ってみるとRAGの改善候補5点をご紹介します!
RAGの仕組み
まずは、RAGの全体像を書いてみます。ここでは少し細かめに記載してみます。
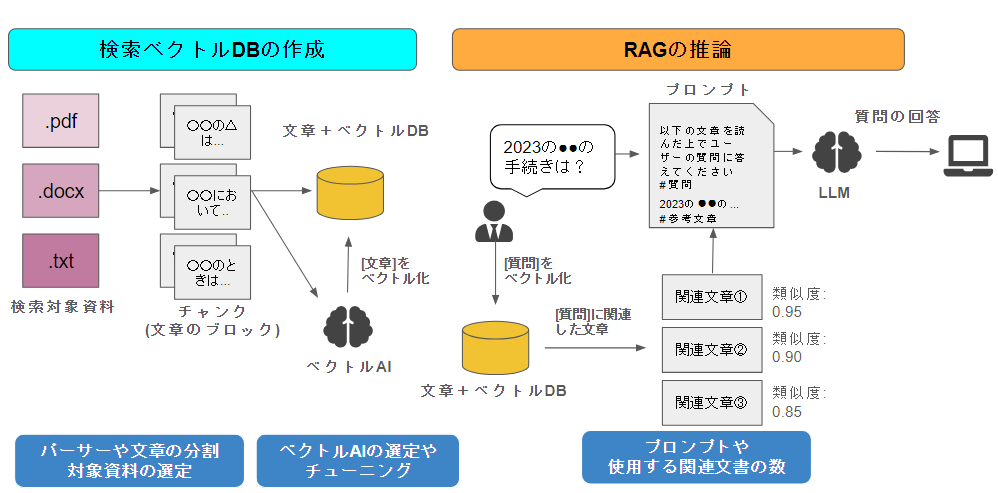
流れを追っていくと
- [事前に一度のみ]pdfやdocxなどのファイルを文章に変えて、チャンクに切ります。チャンクとは文章のブロックで、LLMのトークン上限に触れないように小さな単位に分割することです。
- [事前に一度のみ]このチャンクを文章ベクトルに変えます。有名なのは、OpenAI-ada-002系です。
- [質問時]ユーザーからの質問をベクトルに変換します。この質問ベクトルと、文章ベクトルで類似度を測って、類似している関連文章を数件、抽出します。
- [質問時]この数件の関連文章をプロンプトに入れて、参考文章付き回答生成プロンプトを作成します。あとはこのプロンプトでLLMに回答してもらいます。
というステップで処理します♪
RAGを改善したい場合、全体的なアーキテクチャを把握しておくことが大事であるため、細かめに記載してみました🍖
RAGの改善候補
①ベクトル検索精度が悪い
Azure OpenAI(AOAI)を活用する場合、openai-ada-002を使用して検証することも多いですが、このopenai-ada-002は別に、検索精度が優れているわけではありません。
私の経験上は以下のような検索に特化したモデルでくみ上げることで精度が良くなることを確認しています♪
3つとも、MITやapache2.0で公開されており、商用利用可能です♪
「文章間の類似度」だけでベクトル検索するのは限界があり、工夫をしたベクトル検索用のモデルが活躍します🍕
②資料やチャンク数が多すぎる
資料やチャンクが多すぎると以下のネガティブポイントがあります。
- ベクトル検索の場合、資料は入れれば入れるほどヒットする確率は下がります。少なくともあがることはありません。検索精度が低いRAGシステムは活用されません。
- ユーザー視点で考えた際に「RAGの対象の資料がイメージできない」のはとても活用されづらいです。そもそも私たちは、「社内の情報をLLMに聞いても回答できない」ことを知っています。もし「社内情報を何でも答えるRAGシステム」があっても、そもそも質問されなければ意味がありません。そのため、「社内情報を何でも答えるRAGシステム」よりも「社内の出張のことならなんでも答えられるRAGシステム」のほうがユーザーとしては便利に活用することができるでしょう。
管理は大変かもしれませんが、少人数の管理で大多数の社員様が便利になるならよろしいのではないでしょうか🍰
③資料のパースがイマイチ
| イマイチ例 | イマイチ内容 | 改善例 |
| 図 | ・図中の文字が完全に読み取れていない ・図中の矢印や「〇」が読み取れない ・図が複雑すぎて人間でも読み取りが難しい | 図は現状は、 ・無視する ・人力で文章形式に修正する ・VLM(GPT4V)を使ってみる などが取り組まれていますが、まだまだこれからです。 |
| 表 | ・フォーマットが完全に崩れている(行や列など) ・結合されたセルが処理できない | 表はシンプルな図であれば機械的に文字起こしする場合もあります。一方結合等のある表の場合は、こちらも無視したり、人力修正になる場合もあります。 |
| 文章前処理 | ・「半角スペース」「全角スペース」「改行コード」などが多すぎる ・ページマタギでやヘッダーフッターが悪さする場合がある | ここは、普通にデータを見て、対応してください。一般的な自然言語処理ですから、データ見て、対応していくことが重要です。 |
| チャンクの切れ目 | ・中途半端なところで文章を切ってしまう。 ・チャンクが短すぎる/長すぎる | RecursiveCharacterTextSplitterが私は好みです。こちらを使えば ・「。」や「.」などの区切り文字でチャンク分割が可能 ・文字数ではなくトークン数で分割が可能 など、いい感じです♪ |
世界的に見てもまだまだなところもあり、ここがRAGの難しいところです。ただ、私はローコストで半自動な中途半端なものを作るのであれば、多少の人力を割いてでも良質なデータを作成して良いRAGシステムを作ってみる方が良いのではないかなと思っています🍵
④資料に図や表が多すぎる
根本的には、LLMは文章処理をするモデルですので、”図表だらけの資料”というのはそもそも向いていません。
pdfやdocxなど、自然文で丁寧に説明されている文章をRAGの応用先とするのがいいのかなと思います。
図表が多い場合は、LLMというより画像処理のユースケースに少し近くなってきます。
⑤活用イメージがわいていない
そもそもなのですが、RAGは「質問から回答を生成する」システムです。
一方、「検索が効率的にできる」わけではありません。
たまに、課題が「ファイル見つけるの大変なんだよね」という方がいますが、それはRAGで解決できる問題ではありません。(結局、検索はRAGでも課題になります。)
LLM以前に、社内の活用イメージやRAGの本質的なメリットを捉えてRAGのトライアルをするのがいいように思えます🌍
逆に言うと、RAGに大事なところ(まとめ)
RAGは結局のところ、とても簡素にするとこのようなシンプルな形で表現できます。
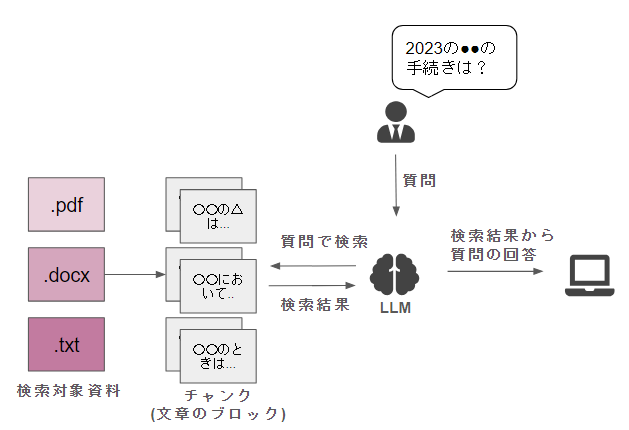
精度に大事なのは、LLM本体のパワーよりも左側の「いかに関連文章を見つけてこられるか」です!
そして、この検索精度を改善する方法が
- ファイルの丁寧な文章化(切れ目や図表の人力パース)
- ベクトル検索モデルの選定
などにつながってきます。
皆様のお役に立てば幸いです♪

