
こんにちは!みうです!MoEについて解説します!
この記事では、正確さよりもわかりやすさ重視で説明致します!
MoEについて、メリットだけでなくデメリットも両方お伝えしたいと思います
MoE(Mixture of Experts)とは
結論から言うと、私はLLMの推論高速化手法の1つと考えるのが1番的確かなと思っています!
| 比較項目 | MoE(mixtralなど) | 密なモデル(llama2-70Bなど) |
| パラメータ (今回の前提) | 同じとする(8×7Bと56Bを比較) | 同じとする(8×7Bと56Bを比較) |
| VRAM (GPU使用量) | GPU使用量は変わらない | GPU使用量は変わらない |
| インフラ費用 (ランニングコスト) | GPU使用量が同じなので、費用も同一 | GPU使用量が同じなので、費用も同一 |
| 速度 | 高速 | MoEよりは低速 |
| 精度 | 密なモデルに匹敵 | 高い |
精度ほぼ保ったまま高速にするが、ランニング費用(インフラ代)は高額のまま、というのが特徴です
推論は以下のようなイメージがよく使われます
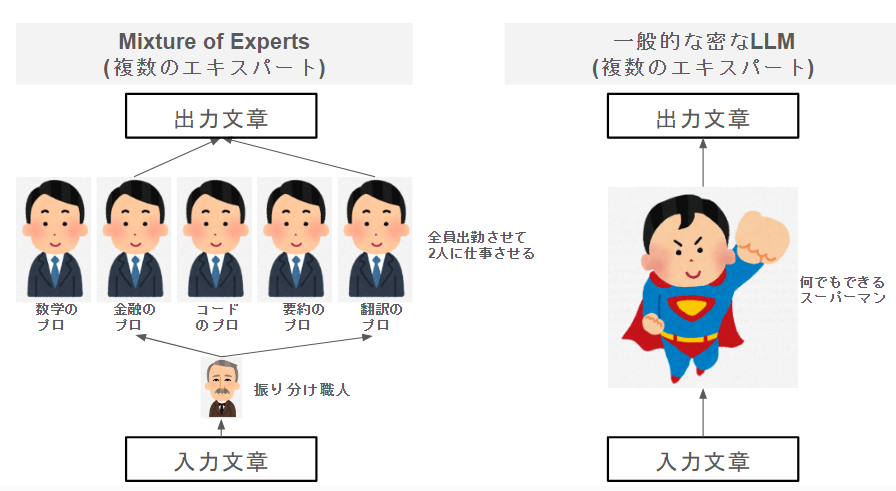
実際には、エキスパートはドメイン毎に割り振りされているわけではないですが、イメージとしてはこんな感じです。
また、一般的なLLMは、5人合わせて1人相当のスーパーマンが推論を行います。
専門家vsスーパーマンの構成にしてみました。エキスパート(専門家)というと凄そうな感じがしますが、実際には右側のスーパーマン一人のほうが精度上は優れています。
MoEの特徴
アーキテクチャの違い
普通のLLMと異なり、MoEには、5人のエキスパートと1人の割り振り役(gate)が居ます。
エキスパート側は単純に割り振られたデータを学習するだけですが、一番大変なのは割り振り役です。教育係みたいなものなので、この割り振り役に工夫した学習が行われています。
Loss関数の違い
通常、LLMは次のトークンの予測確率で学習を行いますが、MoEには追加で2つのロスを使用します
① LLMの次トークン予測
こちらは割愛しますが、一般的なLLMの次のトークンを予測に対して発生するロスです。
② データ平等分散くん【Load Balancing Loss(auxiliary loss)】
ロス関数の数式嫌いですよね。内容だけ説明すると
エキスパート間でトークンをバランスよく分散するために使用されます。ベクトル間のスケーリングされたドット積を使用して計算され、バッチのトークンをエキスパート間で均一にルーティングするように促します。
https://arxiv.org/pdf/2202.08906 翻訳 by ChatGPT
という形です。これがあることで”学習時は極力、各エキスパートに平等にトークンを配分しろよ”という圧力がかかります。
③ ①と②の仲次ぎくん【z-Loss】
②のデータ平等分散くんは良さそうに見えて意外と悪さをします。
AIというのはとても素直ですので、「データ平等分散くんに従っておけば、次トークン予測適当でもロス下がるじゃん!」という低みに流れてしまい、学習が安定しません。このままだと各エキスパートにトークンを分配するのに一生懸命で、肝心の言語生成機能が微妙になってしまいます。
そこで、「データ平等分散くんは仕事はしてほしいけど、全体としてこれだけ頑張ってもダメよ」というのがz-Lossのお仕事です。
この3つの損失関数によって複数のexpertが学習されているんですね♪
エキスパートの中身について
先ほどの図では、数学とか金融とかと書いてみましたが、実際にはそうなっていないことが、論文から発表されています。
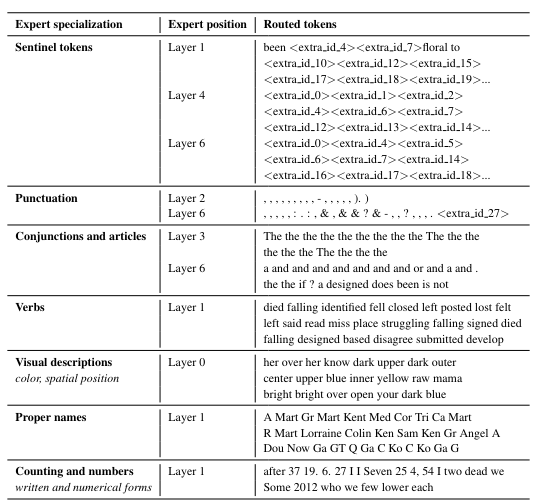

実際には、金融といったドメイン単位ではなく、品詞など単語の性質毎にトークンが割り当てられることがわかります😮
【補足】エキスパートは文単位ではなくトークン単位
このMoEは内部的には、MoEレイヤーという形で実装されます。MoEレイヤーはTransformerの中の1パーツになります。Transformerは、1トークンにつき1予測しますので、MoEのエキスパートも基本は、トークン単位のエキスパートとなります。
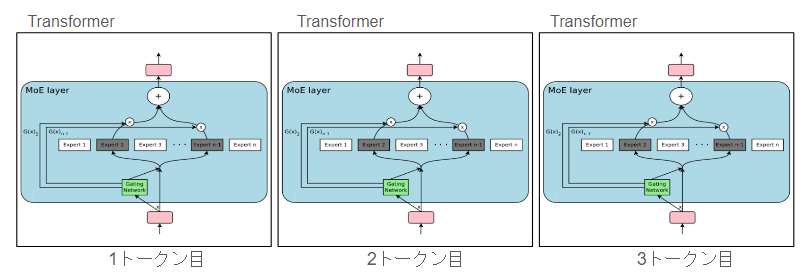
ですので、エキスパート自身も入力文に対する専門家というより、各トークンごとの専門家になります。
また、1トークン目と2トークン目は別のtransformerなので、エキスパートも別です。そのため、文章全体で「金融のエキスパート」のように捉えるのも少し間違っています
“エキスパート”というイメージから少し乖離するかもしれませんが、実際はそういう形です。
私の感想①
MoEのような構造はいつでも上手く機能するテクニックではありません。
図を見るとわかるように、モデルの構造は複雑になります。複雑な構造というのはあまりポジティブに働きません。
例えば、エキスパートは良いのに割り振り役(gate)がぽんこつだったから精度悪化した
なんてことがよく起きるんですよね。なら割り振り役居なければいいかぁ(元の構造に戻る)
今回の調査をする中で、gateは各トークンを5分割にして適当に割り当ててもそこそこ動くかもしれませんね
私の感想②
私の感覚としては「エキスパート2人による良い推論」というより「5人出社待機しているエキスパートのうち2人だけで推論」というドロップアウト的な、効率的な手抜き方法のイメージです。
ただ、以下の背景が重なって効果を発揮していると思われます。
- Scaling-low(パラメータはでかい方が強い)
- パラメータがデカすぎて遅くて使いづらい
この折衷案で出てきた手法なのかなという感覚です。LLMは独特な事情があって面白いですね♪
まとめ
MoEについて何となくご理解頂けたでしょうか!
- エキスパートはトークン単位で文単位ではないこと
- 各エキスパートは金融などドメイン単位というより品詞的な担当の仕方をしていること
は意外な要素だったりするのかなと思っています🙃
本日もお読みいただきありがとうございました!

